通常应用多线程技术时,我们并不会直接创建一个线程,因为系统启动一个新线程的成本是比较高的,涉及与操作系统的交互,而是使用线程池来对线程进行管理,尤其是有很多生命周期很短的线程,线程池会显著提升多线程程序的性能。
本文主要对线程池的源码进行分析,了解了源码,我们才能够更高效的使用线程池,同时出现异常时也能更容易的进行排查。
2.本文篇幅较大,可根据需要跳转到需要的章节阅读
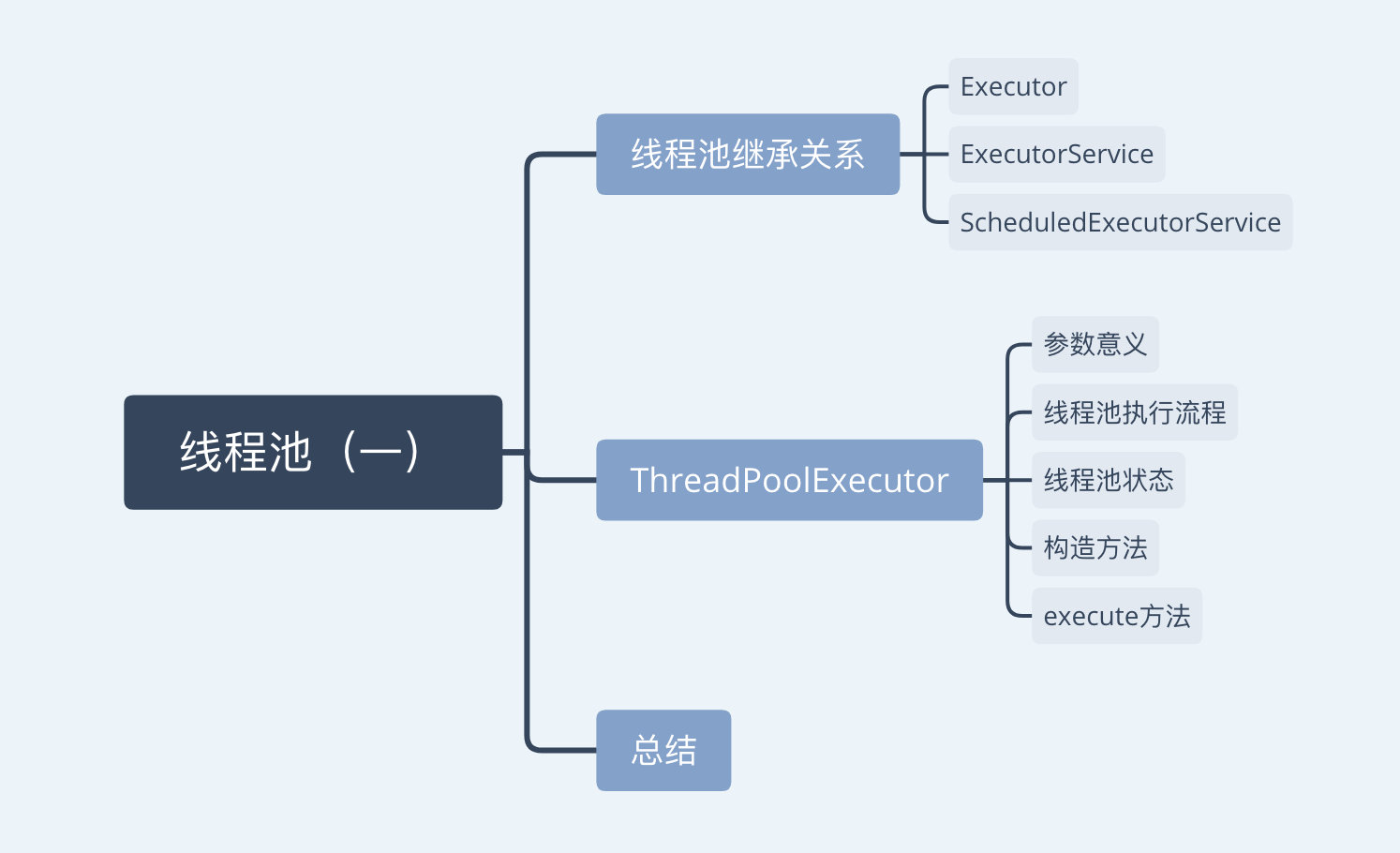
一、线程池的继承关系及接口方法
Executor:是最基础的执行接口;
1 | void execute(Runnable command); |
仅提供一个执行线程使用的方法。这个线程会在未来一段时间进行执行,这个任务可能会执行in a new thread,in a pooled thread,or in the calling thread,和具体的实现相关。
ExecutorService:继承了Executor,并提供了shutdown()、submit()等方法,可以说是真正的线程池接口;
与shutdown相关的方法
1 | /** |
与submit相关的方法
1 | /** |
与invoke相关的方法
1 | /** |
AbstractExecutorService:对ExcutorService中的大多数方法做了基本实现;
TheadPoolExecutor:这个是线程池的具体实现,也是我们代码分析的主要部分;
ScheduledExecutorService:继承了ExecutorService接口,提供与执行周期性任务相关的功能;
1 | /** |
ScheduledThreadPoolExecutor:是可以执行周期性任务的线程池的具体实现;
二、ThreadPoolExecutor分析
构造函数及参数含义
ThreadPoolExecutor提供四个构造函数,但其他三个都是基于下面这构造函数
1 | public ThreadPoolExecutor(int corePoolSize, |
参数含义:
corePoolSize
- 线程池中的核心线程数量,当提交一个任务时,线程池创建一个新线程执行任务,直到当前线程数等于corePoolSize,即使有其他空闲线程能执行新来的任务,也会继续创建新的线程;
- 如果当前线程数为corePoolSize,继续提交的任务被保存到阻塞队列中,等待被执行;
maximumPoolSize
线程池允许线程的最大数量,在阻塞队列被填满后,会创建新的线程执行任务,前提是当前线程数小于maximumPoolSize
当workQueue为无界队列时,maxiumPoolSize则不会起作用,因为新的任务会一直放入到workQueue中
workQueue
- 线程存活时间,当线程没有任务执行时,继续存活的时间,默认情况只对线程数大于corePoolSize是有用。
- 阻塞队列的选择
- ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序,指定队列的最大长度,使用有界队列可以防止资源耗尽,但会出现任务过多时的拒绝问题,需要进行协调。
- LinkedBlockingQueue:一个基于链表结构的有界阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
- SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
- PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
keepAliveTime
线程空闲时的存活时间,默认情况下,该参数只在线程数大于corePoolSize时才有用。
TimeUnit
keepAliveTime的单位
TimeUnit静态类提供常量
threadFactory
- 创建线程的工厂,通过自定义的线程工厂可以给每个新建的线程设置一个具有识别度的线程名。默认为DefaultThreadFactory,自定义可以实现ThreadFactory接口
handler
- 线程池的饱和策略,当阻塞队列满了,且没有空闲的工作线程,如果继续提交任务,必须采取一种策略处理该任务
- 线程池提供如下四种策略
- AbortPolicy:直接抛出异常,默认策略
- CallerRunsPolicy:用调用者所在的线程来执行任务
- DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务
- DiscardPolicy:直接丢弃任务
- 可以根据具体使用场景,实现RejectedExecutionHandler接口,自定义拒绝策略
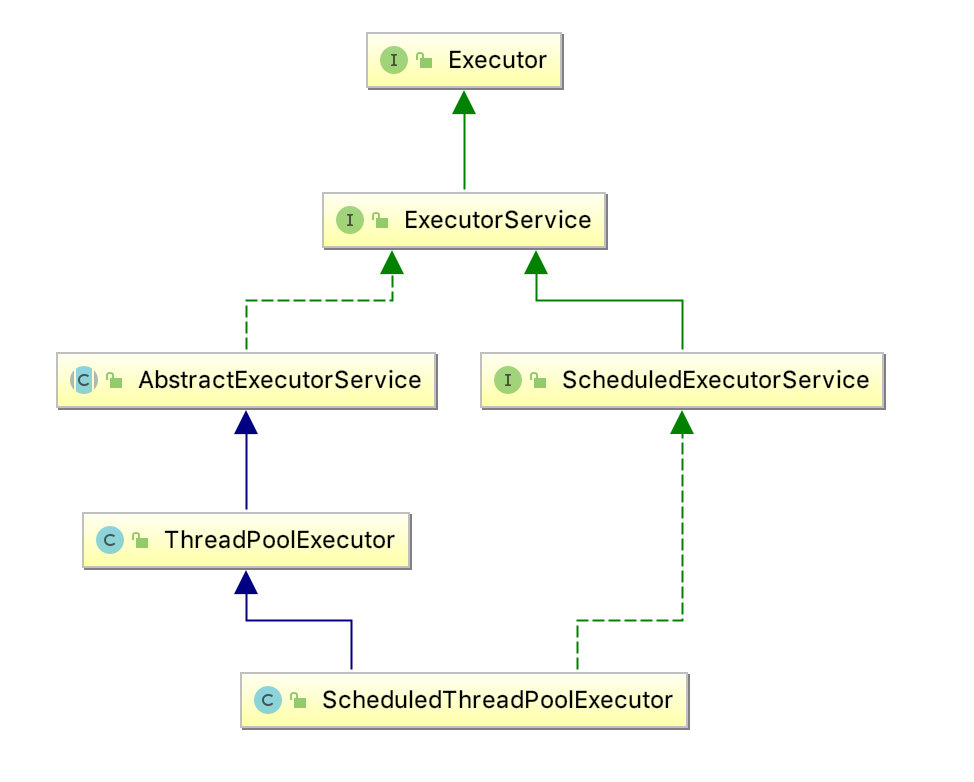
线程池的执行流程
如果当前worker数量小于corePoolSize,则新建一个woker并把当前任务分配给该woker线程
如果当前worker数量大于corePoolSize,则会将任务加入到workerQueue中
如果wokerQueue是有界队列,并且已经填满,则会判断当前woker数量小于maximumPoolSize,如果小于,则新建一个woker并把当前任务分配给该woker线程,成功则返回。
当worker的数量已经等于maximumPoolSize则调用拒绝策略处理该任务。
另外,当线程池中线程大于corePoolSize,并且空闲时间超过keepAliveTime时,将会被移出线程池。
源码分析
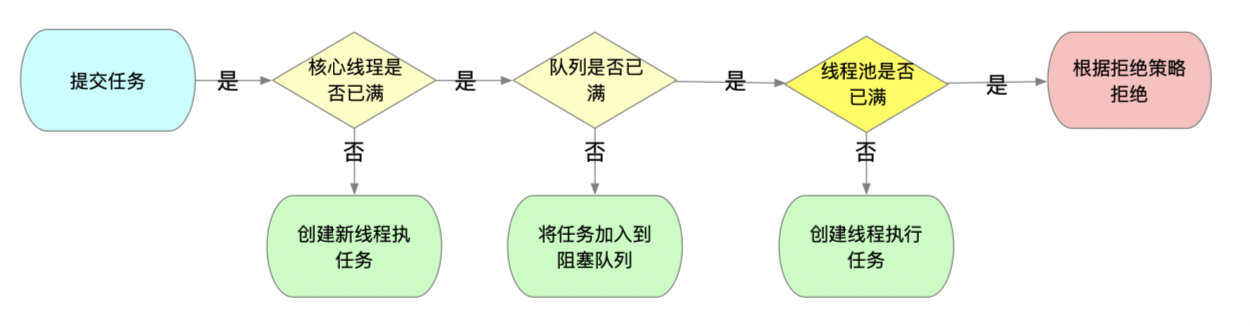
线程池的状态
1 | // ct1是一个原子整数型,其中打包了两个概念概念 |
这张图我只做了一个16位的情况,前两个是补码和非运算后的数据,下面四个是一次简单的计算过程。
构造方法
1 | public ThreadPoolExecutor(int corePoolSize, |
execute方法
1 | // 本方法就是上述线程池执行流程的代码形式 |
addWorker方法
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
return false的条件分析
rs >= SHUTDOWN &&! (rs == SHUTDOWN &&firstTask == null &&! workQueue.isEmpty())如何成立
- 线程池至少是
SHUTDOWN状态,rs>=SHUTDOWN 下面三个条件至少有一个是不成立的
rs == SHUTDOWN &&firstTask == null &&! workQueue.isEmpty()rs == SHUTDOWN前提条件(rs>=SHUTDOWN)–> falsers>SHUTDOWN
这种情况是线程池已经处于STOP、TYDING、TERMINATED状态firstTask == null前提条件rs== SHUTDOWN–>falsefirstTask!=null 这种情况是线程池处于
SHUTDOWN状态,线程池已经不接收新的任务了! workQueue.isEmpty()前提条件rs==SHUTDOWN && firstTask==null–>false 这种情况是线程池处于
SHUTDWON状态,并且新来的任务为null,没必要新开线程
本方法的几种形式
1、addWorker(command, true)
2、addWorker(command, false)
3、addWorker(null, false)
4、addWorker(null, true)
在execute方法中就使用了前3种
第一个:线程数小于corePoolSize时,放一个需要处理的task进Workers Set。如果Workers Set长度超过corePoolSize,就返回false
第二个:当队列被放满时,就尝试将这个新来的task直接放入Workers Set,而此时Workers Set的长度限制是maximumPoolSize。如果线程池也满了的话就返回false
第三个:放入一个空的task进workers Set,长度限制是maximumPoolSize。这样一个task为空的worker在线程执行的时候会去任务队列里拿任务,这样就相当于创建了一个新的线程,只是没有马上分配任务
第四个:这个方法就是放一个null的task进Workers Set,而且是在小于corePoolSize时,如果此时Set中的数量已经达到corePoolSize那就返回false,什么也不干。实际使用中是在prestartAllCoreThreads()方法,这个方法用来为线程池预先启动corePoolSize个worker等待从workQueue中获取任务执行
Worker类
1 | /** |
之所以要在Runnable外面包一层Worker是为了通过Worker来控制中断,而Runnable只需要执行业务逻辑就可以了。
这里我也有一疑问,为什么不允许Worker在runWorker前就被中止呢?为什么呢?runWorker方法
1 | final void runWorker(Worker w) { |
本方法先是使线程进入执行状态,并且可以进行中断,然后循环执行任务,直到getTask()获取不到任务则进行退出。
getTask方法
1 | private Runnable getTask() { |
本方法主要是从阻塞队列中获取任务,在以下状态时会返回null:
- 超过了maximumPoolSize设置的线程数量;
- 线程池被stop
- 线程池被shutdown,并且workQueue空了
- 线程等待任务超时
processWorkerExit
1 | private void processWorkerExit(Worker w, boolean completedAbruptly) { |
三、总结
线程池需要说的东西很多,本文分为两个部分,第一部分是描述线程池的继承关系,第二部分ThreadPoolExecutor源码分析,原理上线程池并没有像HashMap源码那么复杂,重要的是在方法中不断的进行判断线池状态容易让人产生疑惑,本文根据情况选择需要的阅读部分~
参考资料:
注:这里强烈推荐参考资料3,非常完成的线程池分析